They define planning in an unusual manner as using “more computation without additional data to improve predictions and behavior”
The “usual” definition being the use of a (learned) transition and reward model to compute a value function or policy
The reasons they give for why parameteric model-based planning might outperform non-parameteric (experience replay) planning are not that clear to me, but may include:
Inductive bias of the parameteric model (improving generalization)
Improved exploration through use of the model
Improved credit assignment (“backward planning”)
To answer the question, I think the reason MuZero might outperfom DQN is the second reason: that it exhibits better exploration
This isn’t the typical kind of improved exploration through model use that you get with e.g.,
R-max.
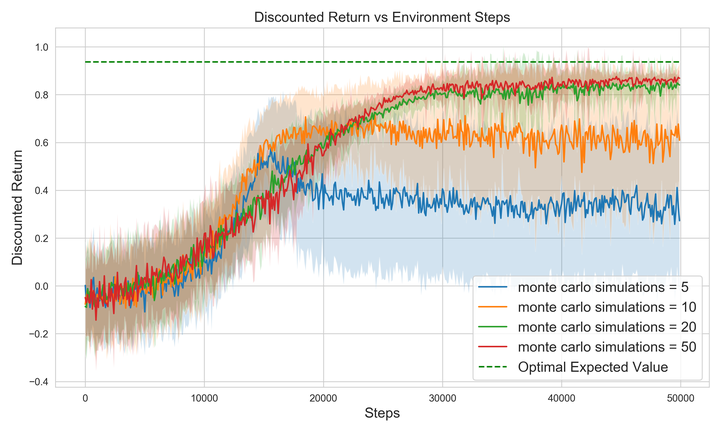
Instead, because the learned value function is approximate, if the learned model is “good enough”, then you can use additional computation to select better actions in the environment than you would if you behaved greedily with respect to the value function itself.
Where “additional computation” means running MCTS.
This means that the actions you take will, on average, be better.
Which intuitively should mean that you’ll learn about the optimal policy and its value function more quickly.
And reach different parts of the state space that have higher value.
Which can be viewed as improved exploration.
This works for the definition of “better” as “more sample efficient”
But that additional computation takes more resources and time, so if you defined “better” as the algorithm that provides the best solution given some amount of time, DQN might outperform MuZero.